GCPにて生成AIを活用した基本的なWebチャットシステム
まえがき
前回の記事でAWSを活用して生成AIの学習もかねて、
RAGを活用した基本的なWebチャットシステムを開発してみましたが、
普段の業務ではGCPでの開発がメインのためGCP版を作ってみました。
そのあたりの情報を共有したいと思います。
目次
概要
フロントエンド側はNginxへReact、TypeScript、Viteをコンテナにて
構成してます。フロントエンド回り特にAWS版と特に大きな変更はありません。
バックエンド側もFastAPI周り特に変更はありません
双方のコンテナともにCloud Runへデプロイしています。
変更となっている点がLangChainからBedrock(Cloude3)呼び出し部分をVertexAI(Gemini)へ変更
KnowledgeBaseを利用したRAGの部分をVertexAISearchへと変更しています。
その他大きな部分での変更はありません。
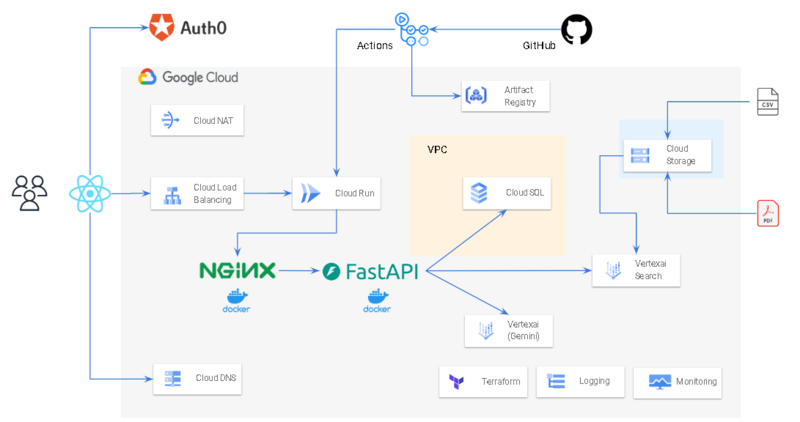
工夫したところ
今回はGCPのCloud Runの機能を最大限に活用するよう心がけています。
具体的には最近リリースされた「VPCダイレクト下り」、サイドカー機能を使い、
NginxコンテナとUviconコンテナをCloud Runの中に構成しています。
またCloud Runはyamlで定義することが可能なため、Github Actionsの中で
テンプレートからenvsubstを使いCloud Run実定義を生成し
デプロイするところまで自動化しています。
使用技術
- 開発環境
- フロントエンド
- Nginx(Vitev5&TypeScriptv5&Reactv18)
- 認証
- Auth0
- バックエンド
- Uvicorn(Pythonv3.11&FastAPI&Langchain)
- CI/CD
- GitHub Actions
- インフラGCP
- CloudRun、CloudLB、CloudDNS、CloudDomains、CloudSQL、VPC、
- CloudNAT、VertexAI Search、VertexAI(Gemini)
実装機能一覧
- Auth0 Googleログイン機能
- ユーザ情報登録、編集機能
- VertexAI Gemini1.5を利用したチャット応答機能
- VertexAI Search RAG 活用機能
- 生成AIへの前提条件設定※埋め込み
- 生成AIに過去の会話履歴を踏まえて応答させる機能
- チャットセッションごとの会話履歴の登録、削除機能
まとめ
コンテナの活用、及び生成AIに関するところはLangChainを利用していたため
修正する箇所はほとんどなく容易にAWS→GCPへ環境を移行することができました。
異なるクラウド環境を構築することで改めてGCPに関してもとても勉強にもなりました。
それぞれのクラウドの良さや違いも自分ので手を動かして実施してみることで
改めて体感することができると思います。
AWSにて生成AIを活用した基本的なWebチャットシステム
まえがき
学習したもののアプトプットとしてクラウドからアプリケーションまで
ワンストップで開発したいと思っていたところ、とっかかりとして生成AIが昨今とても流行ってたため
生成AIの学習もかねて、RAGを活用した基本的なWebチャットシステムを開発してみました。
今回も出来る限りスコープを絞り、作りきることを目的にして最小限の機能で
リリースできるものとしています。
目次
概要
フロントエンド側はNginxへReact、TypeScript、Viteをコンテナにて
構成してます。SPA構成のシンプルな仕組みをとっているため
Next.js等フレームワークは今回使用していません。
バックエンド側は今回初めてFastAPIを利用して開発してみました。
FastAPIは実際学習コストがとても低くAPIに特化している分、覚えることも限られているため
とてもスムーズにAPI開発を進めることができました。
認証はドキュメントが充実しており開発のスピードを優先してAuth0で実装してます
フロントエンド側で取得したアクセストークンをバックエンド側でチェックしています。

工夫したところ
生成AI周りはLangChainを利用して汎用性、可搬性を高めることを意識してます。
またインフラに関してはApp Runnerにしようか迷いましたが、小回りが効くFargateを採用し、
一方でコスト削減を目的にNatGatewayを削除し
セキュリティグループでそれぞれのプロダクトをガードすることでシンプルかつセキュア、低コストな
環境とすることを心がけました。
使用技術
- 開発環境
- フロントエンド
- Nginx(Vitev5&TypeScriptv5&Reactv18)
- 認証
- Auth0
- バックエンド
- Uvicorn(Pythonv3.11&FastAPI&Langchain)
- CICD
- GitHub Actions
- インフラAWS
実装機能一覧
- Auth0 Googleログイン機能
- ユーザ情報登録、編集機能
- Bedrock Cloude3を利用したチャット応答機能
- Bedrock KnowledgeBaseRAG 活用機能
- 生成AIへの前提条件設定※埋め込み
- 生成AIに過去の会話履歴を踏まえて応答させる機能
- チャットセッションごとの会話履歴の登録、削除機能
まとめ
フロントエンドからバックエンドのAPI、クラウド環境の構築まで
フルスタックで1から開発することでスモールながらもリリースできた時はなかなか達成感がありました。
思いのほか大変でしたが、思いのほか力の付く体験でした!
今回はインフラにAWSを利用しましたが、普段業務でのメインクラウドであるGCPでも
同様の環境を構築してみましたので、また別の記事で共有したいと思います!
Next.jsで自己紹介サイトを作成
まえがき
何か一つ簡単なものでも形にして外にアウトップットしようと
常々思ってはいたのですが、なかなか実行はできていませんでした。
やはり外へ公開となると、一気にハードルが上がってしまい
二の足を踏んでしまう方もいるのではないでしょうか?
恥ずかしながら自分もその一人です^^;
ただ今回、たまたま案件でReactを触る機会があり、
React未経験だったこともありかなり苦労して学習したところでした。
背景もあって、せっかく勉強したReactの個人的な最初のアウトプットとして
出来る限りハードルを下げて短期間に小さく形になるもの
リリースできるものとして、自己紹介のWebサイトを題材してみました。
ちなみに自分のフロント回りのスキルはこんな程度
- CSS、Sass、HTMLが書ける
- TailWindを利用した簡単なデザイン、レイアウト
- Vue.js(2~3) を使用したフロントエンド開発経験が数年
- TypeScriptが書ける
目次
概要
スタートはReact&TypeScript&Viteを利用し
とにかくシンプルにシングルページでトップページ、自己紹介、
略歴、スキル、成果物(と言ってもほとんどないですが..^^;)
の構成でそれぞれセクションごとにコンポーネントを分けて作成しました。
定番の「トップページへ戻る」や「Intersection Observe API」を利用した効果
に関してはVueでコンポーネントを実装した経験があったため
学習がてらそれらを書き換えてみました。
最後にどーせなら特にホットなNext.js(13.4)を利用してみようと思い
公式サイトを見ながらVite上で作った物をNext.jsへ移行して
動く状態に持っていきました。
※丁度NextがPage RouterからApp Routerへの過渡期だったこともあり
情報が混在しており、混乱したりもしましたが、公式ドキュメントを見ながら
App Routerへ乗せることができました。
最後に公開方法はGithub Pagesを使おうと持っていたのですが
Publicリポジトリである必要があったりと、条件があったため
Next.jsと相性の良いVercelの公開サービスを利用することにしました。
こちらもGitHubと連携、CI/CDも非常に簡単でほとんど迷うことなく
リリースまでもっていくことができました。
※こちらがサイトです
www.techpiro.net
使用技術
まとめ
Nextを使ったアプリケーションとはいきませんが、
静的ページを比較的スムーズに公開することができました。
ステート、ロジック、SSR、バックエンドと連携といったことは一切していないので本当に、
さわり部分ではありますが、Reactを活用して何かを形にして公開する最初の一歩としては
ハードルはぐっと下がりますので、キャリアの棚卸がてら自己紹介サイトは
自分のような入門者の方もとてもおすすめです!
AWS Lamdbaを利用したゴミ出し通知サービス
まえがき
自分の地域では普段資源ごみのタイミングが第N曜日となってまして、
月に2回ほどビン・缶・雑誌など出すタイミングがありますが、
よく忘れてしまい缶などがたまって困っていました^^;
この課題を勉強がてら、AWSを活用して各サービスを組み合わせて解決してみようと思います!
目次
概要
EventBridgeを1時間ごとにスケジュール実行するよう設定し、EventBridgeからLamdbaが呼ばれます。
呼ばれたLamdbaの中でS3上に配置してあるschedule.csvから
通知条件を取得しcsvの中の条件が一致する場合はメッセージを
LineNotifyを通じて自身のLineに通知します。
LamdbaのデプロイはCodePiplineを利用して自動化しています。
Lamdbaはコンテナがサポートされたとのことだったので
ECS同様の方法でbuildspec.ymlにビルドからデプロイまで記述してみました。

前提条件
- VSCode、Ubuntu(WSL2)、Docker、Docker-compose設定済みであること
- AWSCLIが設定済みであること
- Bitbucket or Github or CodeCommitへpushが出来ること
- LineNotifyは設定例がたくさんありますので対象外としてます
プログラム説明
ディレクトリ構成
/garbage
/src
index. py
buildspec.yml
docker-compose.yml
Dockerfile
requirements.txt
src配下に今回実行するindex.pyファイルを配置しています
buildspec.yml
version: 0.2 phases: pre_build: commands: - echo Logging in to Amazon ECR... - aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin "${AWS_ACCOUNT_ID}.dkr.ecr.ap-northeast-1.amazonaws.com" build: commands: - echo Build started on `date` - echo Building the Docker image... - docker build -t "${REPOSITORY_NAME}:latest" . - docker tag "${REPOSITORY_NAME}:latest" "${REPOSITORY_URI}" post_build: commands: - echo Build completed on `date` - echo Pushing the Docker image... - docker push "${REPOSITORY_URI}" - echo Update garbage lamdba ... - aws lambda update-function-code --function-name "${LAMDBA_NAME}" --image-uri "${REPOSITORY_URI}:latest" --publish
buildspec.ymlではECRへのログイン、コンテナ形式のlamdbaのビルド、ECRへのpush 最後にpost_buildの中でlamdba関数のデプロイを実施しています。
Dockerfile
FROM public.ecr.aws/lambda/python:3.9
COPY ./src ${LAMBDA_TASK_ROOT}
COPY requirements.txt .
RUN pip3 install -r requirements.txt
CMD [ "index.handler" ]
lamdbaがコンテナをサポートしたためECRからlamdbaコンテナイメージ取得し、 ソースを含めてビルドします。
docker-compose.yml
version: "3" services: lamdba: container_name: "garbage" build: . volumes: - ./src:/var/task ports: - "9000:8080" env_file: - variables.env command: index.handler
開発用にローカルのsrcディレクトリをlamdbaの実行ディレクトリにマウントしています。
#Lineトークン ACCESS_TOKEN=xxxxxxxxxxxxxxxxxx AWS_ACCESS_KEY_ID=xxxxxxxxxxxxxxxxxx AWS_SECRET_ACCESS_KEY=xxxxxxxxxxxxxxxxxx TZ=Asia/Tokyo
開発環境用の環境変数は外だししvariables.envに記述しています。
index.py
import os import io import json import requests import boto3 import pandas as pd import datetime # Line Notify ACCESS_TOKEN = os.environ["ACCESS_TOKEN"] HEADERS = {"Authorization": "Bearer {}".format(ACCESS_TOKEN)} URL = "https://notify-api.line.me/api/notify" s3 = boto3.resource('s3') def handler(event, context): print("==>> Start garbage lamdba") schedule_obj = s3.Object( "garbage-notice-master-bucket", "schedule.csv" ) schedule_csv_string = schedule_obj.get()['Body'].read().decode("utf-8") s_df = pd.read_csv(io.StringIO(schedule_csv_string)) s_df['execdate'] = pd.to_datetime(s_df['execdate']) #現在の時間を日付型で取得 date_now =datetime.datetime.now() #schedule.csv上にあるレコード分ループ for s_data in s_df.itertuples(): #実行条件日を取得 exec_date = s_data.execdate #事前に通知したい日数を加算して現在日時とする add_date_now = date_now + datetime.timedelta(days=s_data.ago) #実行条件日の年月日のみ現在日付にリプレイス exec_date = s_data.execdate.replace(year=add_date_now.year, month=add_date_now.month, day=add_date_now.day) #リプレイスした日付と、現在日時の差を計算 date_diff = exec_date - add_date_now #実行条件日と加算した現在日時の差が180分以内かチェック if date_diff < datetime.timedelta(minutes=180) and exec_date > add_date_now: #CSV実行条件の曜日と、加算した現在日時の曜日が同じかチェック if s_data.execdate.isoweekday() == add_date_now.isoweekday(): #加算した現在日時が第何週か算出 CSVの第何週条件と同じかチェック caloc_nthday = (add_date_now.day - 1) // 7 + 1 if caloc_nthday == s_data.nthdayofweek: #LINEに通知 send_data = {'message': "{} は資源ごみを出す日です!ビン・缶・雑誌など!".format('{0:%Y-%m-%d}'.format(add_date_now))} requests.post(URL, headers=HEADERS, data=send_data) print("==>> End garbage lamdba") return { "statusCode": 200, "body": json.dumps( { "message": "Complete!", } ), }
メインの処理を記述しているPythonのコードになります。
ACCESS_TOKENはLineNotifyから取得した環境変数へセットしています。
またS3へ手動でアップロードしたschedule.csvを直接参照し、
条件を取得後pandasのdataframeへ入れて値を取得しています。
schedule.csvの中のexecdateが実行対象日情報
※今回は第何週の条件のため時刻を条件として利用
nthdayofweekが第何週かの情報、agoが何日前に通知するかの情報を保持しています。
schedule.csv

EventBrigeからキックされた現在時刻に事前通知条件を加算し、現在時刻として
現在時刻が取得した条件に一致するする場合通知を行うという仕組みです。
時刻をそのままにして実行対象日を現在の年、月、日で置き換えた日付を
実行条件日(exec_date)としています。
#リプレイスした日付と、現在日時の差を計算 date_diff = exec_date - add_date_now #実行条件日と加算した現在日時の差が180分以内かチェック if date_diff < datetime.timedelta(minutes=120) and exec_date > add_date_now:
実行条件日と現在の時刻(事前通知日数を加算したadd_date_now)と比較して3時間以内かチェック。
#CSV実行条件の曜日と、加算した現在日時の曜日が同じかチェック if s_data.execdate.isoweekday() == add_date_now.isoweekday(): #加算した現在日時が第何週か算出 CSVの第何週条件と同じかチェック caloc_nthday = (add_date_now.day - 1) // 7 + 1 if caloc_nthday == s_data.nthdayofweek:
あとは実行条件日と現在の時刻の曜日が同じであること、第N週を現在の時刻から算出し、
schedule.csvのnthdayofweekの値を同じであるか確認し同じであれば LineNotifyを 通じて通知をします。
AWS側の設定
■ElasticContainerRegistoryの設定
まずはECRへ手動でLamdbaイメージをpushします。
プライベート&リポジトリを入力して作成します。
作成したリポジトリを選択してプッシュコマンドを表示を確認してAWSCLIよりイメージをプッシュします。
※コマンドが表示されるためそれをそのまま入力便利!
■Lamdbaの設定
Lamdba関数を手動で先ほどのコンテナイメージを元に作成します。
Lambda>関数>関数の作成
- コンテナイメージを選択
- 関数名を入力
- イメージを参照より先ほどpushしたイメージを選択
- アーキテクチャはデフォルト
- 実行ロール※デフォルトで作成されたロールに
S3へのアクセスが必要なためS3への読み取りポリシーを付与します
関数を作成を押下して作成されていることを確認します。
Lambda>関数>作成された関数名を選択
- 設定
- 環境変数
- ACCESS_TOKEN=LineNotifyで取得したトークン
- TZ=Asia/Tokyo
■EventBrigeの設定
Lamdbaを定期実行するスケジュールを設定します。
Amazon EventBridge>ルール>ルールを作成
ルールの詳細を定義
- 名前を入力します
- イベントバスはdefaultを選択
- ルールタイプはスケジュールを選択
スケジュールを定義

ターゲットを選択
- AWSサービスを選択
- Lamdba関数を選択
- 機能 ⇒ 作成したlamdbaの関数を選択します。
これで手動でLamdbaをコンテナ形式でデプロイし、定期的に実行できる仕組みができました。
次はCodePiplineを使って先ほど手動で実施した作業を自動でデプロイできるようにします。
■CodePiplineの設定
デベロッパー用ツール>CodePipeline>パイプライン>新規のパイプラインを作成する
パイプラインの設定を選択する

ソースステージを追加する
- ソースプロバイダ⇒Bicbucket
- 接続⇒Bicbucketへの接続を作成してセット
- リポジトリ名を選択
- ブランチ名を選択
 ※変更時にパイプラインの実行はしたくなかったためチェックを外しました。
※変更時にパイプラインの実行はしたくなかったためチェックを外しました。
ビルドステージを追加する
- プロバイダーを構築する⇒AWSCodeBuildを選択
- リージョン⇒アジアパシフィック
- プロジェクトを作成をクリックしてCodeBuild作成画面へ
デベロッパー用ツール>CodeBuild>ビルドプロジェクト>ビルドプロジェクトを作成する
プロジェクトの設定
- プロジェクト名を入力
環境
- 環境イメージ⇒マネージド型
- オペレーティングシステム⇒AmazonLinux2
- ランタイム⇒スタンダード
- イメージ⇒aws/codebuild/amazonlinux2-aarch63-standard:2.0
- イメージのバージョン⇒常に最新
- 特権付与⇒チェック
- サービスロールは新規作成
- AmazonEC2ContainerRegistryPowerUser、AWSLambda_FullAccess2つポリシーを追加

Buildspec
- buildspec ファイルを使用する
※buildspecファイルを使用するを選択し作成したbuildspec.ymlを参照してもらいます。
ログ
- CloudWatch Logsチェック
※CloudWatch Logsが有効になっていることを確認します。
デベロッパー用ツール>CodePipeline>パイプライン>新規のパイプラインを作成する
ビルドステージを追加する
※CodeBuildの設定を完了し、CodePipline側へ作成されたプロジェクトがセットされます。
lamdbaへのデプロイはbuildspec.ymlの中で実施してしまうため、
ビルドステージをスキップして完了します。
■CodePiplineの実行
デベロッパー用ツール>CodePipeline>パイプライン
より作成したパイプラインを選択し「変更をリリース」を押下デプロイが成功すれば完了です。
まとめ
身近な課題を題材に設定してみましたが、Python,S3,EventBridge,CodePipline,CodeBuild,Lamdba,
コンテナ,Git,LineNotifyと基本的ですが意外に多くのプロダクトを扱ったことで
基礎理解がとても深まったと思います。
ゴミ忘れも解決でき一石二鳥で有意義でした。
少しでもどなたかの参考になれば幸いです。
参考URL
https://dev.classmethod.jp/articles/get-s3-object-with-python-in-lambda/#toc-3
https://dev.classmethod.jp/articles/tried-using-line-notify-with-lambda-to-notify-the-appointment/
